| 프레임워크 | 장점 | 단점 |
| Theano |
|
|
| Torch |
|
|
| TensorFlow |
|
|
| Caffe |
|
|
| MxNet |
|
|
분류 전체보기
- 딥 러닝을 위한 프레임워크 비교 2018.10.30
- Lucene(루씬)/Solr(솔라)/Nutch(넛츠) 2018.10.30
- 딥러닝, 머신러닝의 차이점? 2018.10.30
- Solr vs ElasticSearch 비교 2018.10.30
- 성공적인 인공지능(AI) 적용을 위한 단계 2018.10.30
- Ucloud 디스크 마운트 2018.10.30
딥 러닝을 위한 프레임워크 비교
2018. 10. 30. 20:13
Lucene(루씬)/Solr(솔라)/Nutch(넛츠)
2018. 10. 30. 19:45
Lucene(루씬)
검색 엔진의 가장 중요한 부분을 담당하는 "색인" 과 "검색" 을 위한 자바로 개발된 라이브러리 이다.
아파치 재단에서 만들어진 프로젝트 이고, 다양한 플랫폼을 지원한다.
Solr(솔라)
솔라는 파일을 인덱스하는 검색엔진으로 XML 요청을 HTTP를 통해 보내는 웹 서비스 API가 있는 검색 서버이다.
그러므로 솔라 검색서버 URL을 사용하여 인터넷을 통해 (HTTP) 파일을 질의하여 인덱스하는 어느 곳에서나 접근할 수 있다.
또한 다른 솔라 검색 서버로 캐싱과 복사가 가능한 최적화된 검색 서버다.
Nutch(넛츠)
오픈소스 웹 검색 소프트웨어로 웹 크롤러의 기능을 제공하고, 수집된 정보들은 루씬을 통하여 검색이 이루어 진다.
정리하자면
루씬은 검색을 위한 API,
솔라는 검색서버,
넛츠는 자료/정보를 수집하는 크롤러
인 셈이다.
'IT-기타(미분류)' 카테고리의 다른 글
| 10가지 소프트웨어 아키텍처 패턴 요약 (0) | 2020.01.28 |
|---|---|
| 딥러닝, 머신러닝의 차이점? (0) | 2018.10.30 |
| Solr vs ElasticSearch 비교 (0) | 2018.10.30 |
딥러닝, 머신러닝의 차이점?
2018. 10. 30. 19:39
개요

1. 머신러닝(Machine Learning)과 딥러닝(DeepLearning)이 무엇일까요?
1.1 머신러닝(Machine Learning)이 무엇일까요?


1.2 딥러닝(Deep Learning)이 무엇일까요?


2. 머신러닝과 딥러닝의 비교
2.1 데이터 의존도(Data dependencies)

2.2 하드웨어 의존도(Hardware dependencies)
2.3 Feature engineering

2.4 문제 해결 접근법(Problem Solving approach)

2.5 실행 시간(Execution time)
2.6 해석력(Interpretability)
3. 머신러닝과 딥러닝은 현재 어디서 쓰이고 있나?
'IT-기타(미분류)' 카테고리의 다른 글
| 10가지 소프트웨어 아키텍처 패턴 요약 (0) | 2020.01.28 |
|---|---|
| Lucene(루씬)/Solr(솔라)/Nutch(넛츠) (0) | 2018.10.30 |
| Solr vs ElasticSearch 비교 (0) | 2018.10.30 |
Solr vs ElasticSearch 비교
2018. 10. 30. 19:06
Solr
사이즈가 큰 데이터 검색에 용이에 문서 검색에 적합하나 색인주기가 느림 (주로 문서검색용)
ElasticSearch
사이즈가 작은 데이터에 대한 속성검색/연관검색/실시간 검색에 용이함 (주요 커머스검색용)
| Solr search ( 쏠라 ) | Elasticsearch ( 엘라스틱 ) | ||
| 개발사 | Apache Software Foundation | Elasticsearch | |
| 노드 1) 컨트롤 주체 | Apache ZooKeeper (별도 프로그램) -> 구동 시 리소스 부하 / 운영 중 스키마 변경 불가 | 자체 Node (마스터노드) -> 구동 시 부하 적음 / 운영 중 스키마 변경 가능 | |
| 샤드 2) 변경 방식 | 별도의 노드 분할 처리 필요(서버 재구동 필요) | 자동 노드 분할(서버 구동 불필요) | |
| 색인업데이트 방식 | 전체 데이터를 캐시로 추가 저장 | 변경 데이터만 캐시로 추가 저장 | |
| 개발언어 | JSON (limited), XML (limited),URL parameters | JSON | |
| 연동가능 분석모듈 (ECOsystem) | 주로 Banana, Zeppelin with Community | JSon 지원 모듈이면 OK(ex. Kibana, Grafana 등) | |
| 주요 활용영역 | 문서 원문 검색 | 상품검색 / 이상징후 감지 & 모니터링 | |
| 속도 | 검색 | 느림 | 빠름 |
| 색인 | 수 십분 | 초 단위 | |
| 분석 | 준실시간 | 실시간 | |
| 장점 | •안정화 단계의 검색•사이즈가 큰 장문 데이터 검색에 용이 | •실시간 색인 가능•계층 구조의 다양한 속성 검색/연관검색 가능 | |
| 단점 | •색인 주기 느림•계층 구조의 속성 검색 힘듦 | •사이즈가 큰 장문 데이터 검색 시 속도 저하 | |
주1) 노드(Node) : 분산처리 구조 상 서버와 유사한 개념의 구분 단위
주2) 샤드(Shard) : 분산구조 상 인덱스 단위로서 단일 노드엔 여러 개의 샤드가 존재
'IT-기타(미분류)' 카테고리의 다른 글
| 10가지 소프트웨어 아키텍처 패턴 요약 (0) | 2020.01.28 |
|---|---|
| Lucene(루씬)/Solr(솔라)/Nutch(넛츠) (0) | 2018.10.30 |
| 딥러닝, 머신러닝의 차이점? (0) | 2018.10.30 |
성공적인 인공지능(AI) 적용을 위한 단계
2018. 10. 30. 19:05
AI를 기업의 비즈니스에 적용할 기가 막힌 아이디어가 있다고 해도 이를 기업에 적용 가능한 솔루션으로 성공적으로 구현하기 위해서는 기업 구성원의 마음가짐 변화와 추진을 위한 적극적인 리더십의 확보, 그리고 기업 업무 전반에 걸친 지원팀의 구성이 선결되어야 한다. AI 적용을 비롯한 기업의 디지털 트랜스포메이션이 성공하기 위해서는 데이터와 IT 기술 인프라를 통합하여야 하며 데이터와 인프라에 대한 전반적인 통합 및 관리 능력을 확보하지 못한 상황이라면 섣불리 AI를 적용하겠다고 뛰어드는 것은 바람직하지 않다. 기업이 이미 빅데이터를 효과적으로 활용할 수 있는 기술과 업무 응용 능력을 갖추었다고 판단되지 않으면 AI 적용은 시기상조다. 데이터에 대한 이해와 활용능력이 없이 AI 도입을 추진하는 것은 성공하기 어렵다.
그리고 기업 오너 또는 경영진이 스스로 통찰력과 판단력이 뛰어나다고 과신하고 조직 전체가 상명하복의 문화에 젖어 있다면 성공적인 AI의 적용이 어려워진다. 기업 경영진이 데이터와 팩트에 기반한 의사결정이 직관에 의한 결정보다 미래의 비즈니스를 위해 더 효율적이라고 공감할 때가 AI 도입을 추진해야 할 시점이다. 아울러 성공적인 AI의 도입을 위해서는 기업 전 조직의 적극적인 협조가 필요하므로 AI 도입에 따른 일부 부서의 두려움과 반감을 불식시키는 공감대의 형성이 선결되어야 한다.
AI 도입을 위한 기업 문화의 형성이 이루어졌다면 본격적으로 기술적인 문제에 대한 접근이 필요하다. AI의 구현을 위한 머신러닝을 포함한 기술적 역량은 기업의 기존 전통적인 정보시스템을 성공적으로 구현하고 운영한 기술적 역량과는 근본적으로 다르다. 머신러닝은 고도의 실험적이고 탐구적인 영역으로 구체적인 구현 일정과 성공적 완료 기준을 설정하기 매우 난해한 분야이다. 머신러닝을 위한 개발자에게는 기존의 소프트웨어 개발과 관련된 분야보다 수학과 통계학 분야의 역량이 훨씬 더 많이 요구된다. 그런데 현재 이런 역량을 갖춘 개발자는 구하는 것이 상당히 어렵다. 그리고 해당 기업의 AI 개발자를 구할 때 반드시 기업의 비즈니스 영역에 대한 지식과 관련 데이터에 대한 이해력을 갖춘 인력을 선별하여야 한다.
AI 적용을 위한 기술 조직의 구성이 마무리되면 구체적인 구현 계획을 수립할 단계이다. AI 도입 시 본격적인 투자에 앞서 ‘AI 도입을 통해 어떤 문제를, 왜 해결하려고 하며 이것이 기업에서 우선순위가 높은지, 그리고 문제 해결이 성공적으로 되었다는 것을 어떻게 측정할지에 대한 지표가 있는가?’라는 질문을 해봐야 한다.
AI의 구현은 텐서플로, 파이토치, 케라스 등의 오픈소스 또는 클라우드 서비스를 활용하는 방안과 기업 독자적인 플랫폼을 구축하는 방안이 있으며 기업의 상황에 맞게 선택한다. 적용할 분야가 기업의 장기적인 성장에 핵심적인 영역인지, 기업 내부적으로 기술 역량은 갖추어졌는지, 구체적인 목표 시기는 언제인지, AI 적용을 위한 데이터는 마련되어 있는지 그리고 마지막으로 전체 TCO 측면에서 자체 구축과 외부 솔루션 도입 중 어느 것이 적절한 방안인지 결정하여야 한다. 명심하여야 할 점은 머신러닝이 기업의 모든 분야에 적용할 수 있는 것도 아니며 어떠한 솔루션도 해당 기업의 비즈니스에 바로 적용 가능하지 않다는 점을 인지하여야 한다.
위 단계까지 완료된 상황이라면 이제부터 해당 영역과 관련된 데이터를 수집하고 준비할 단계이다. 기업 비즈니스 관련 영역의 문제를 AI를 이용하여 성공적으로 해결하기 위해서는 해당 문제를 어떻게 정의하고 정의된 문제와 관련하여 왜곡되지 않고 편향적이지 않은 데이터를 정확하게 수집, 축적할 수 있느냐 없느냐에 AI 적용 성공 여부가 달려 있다고 해도 과언이 아니다.
그다음 단계는 AI 구현을 위한 머신러닝 모델을 개발하는 것이다. 현재 머신러닝은 아직 초기 발전단계라고 볼 수 있으며 지속해서 다양한 기술이 실험되고 개발되고 있는 분야이다. 또한 머신러닝이 모든 문제를 해결할 수 있는 만능 도구도 아니다. 따라서 적절한 모델을 선택하고 기업 내의 데이터를 통해 학습, 발전시켜야 한다. 머신러닝에 있어 데이터의 정확도가 AI의 정확도를 좌우한다. 또한 구현된 모델의 지향 범위가 너무 좁지도, 넓지도 않아야 최적의 결과를 얻을 수 있다. 다음의 그림은 머신러닝을 데이터를 이용해 지속해서 학습시키는 단계를 반복 사이클로 표현한 것이다.
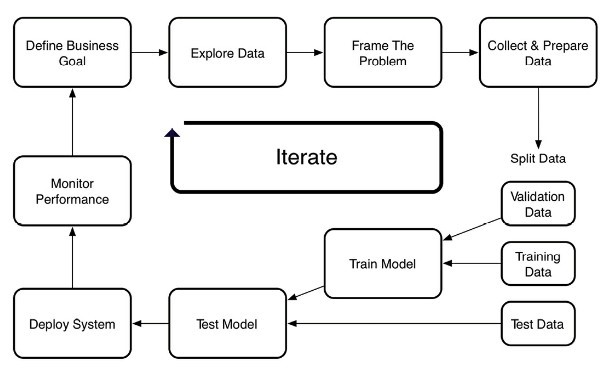
기업의 AI 도입을 위한 단계는 다음과 같이 다섯 단계로 요약한다.
1. AI 도입을 위한 기업 내 환경과 문화를 구축한다.
2. AI 도입을 위한 기술 조직을 구성한다.
3. 구체적인 구현 일정 및 방법을 수립한다.
4. 데이터를 수집하고 준비한다.
5. 머신러닝 모델을 실험하고 학습시키고 문제점을 찾아 모델을 개선한다. 이 단계를 반복적으로 지속하여 원하는 문제를 해결하는 AI 시스템을 완성한다.
보다 상세한 내용은 서적을 참고하시기 바랍니다.
[참고] Yao, Mariya. Applied Artificial Intelligence: A Handbook For Business Leaders, TOPBOTS, 2018, Kindle Edition.
---------------------------------------------------------------
정철환 칼럼
-> 칼럼 | CPU와 메모리 그리고 SSD
-> 칼럼 | IT리더의 두 가지 유형
-> 칼럼 | 한미 FTA와 소프트웨어 저작권
-> 칼럼 | SW 발전의 원동력 벤처, 왜 국내에서는 힘을 못 쓸까?
->칼럼 | 일기예보와 경영예측
->칼럼 | 국내 소프트웨어 산업에 대한 소고(小考)
->칼럼 | 개인정보보호법에 대한 단상(斷想)
->칼럼 | 소프트웨어 개발자, 미래는 치킨집?
---------------------------------------------------------------
정철환 칼럼
-> 칼럼 | CPU와 메모리 그리고 SSD
-> 칼럼 | IT리더의 두 가지 유형
-> 칼럼 | 한미 FTA와 소프트웨어 저작권
-> 칼럼 | SW 발전의 원동력 벤처, 왜 국내에서는 힘을 못 쓸까?
->칼럼 | 일기예보와 경영예측
->칼럼 | 국내 소프트웨어 산업에 대한 소고(小考)
->칼럼 | 개인정보보호법에 대한 단상(斷想)
->칼럼 | 소프트웨어 개발자, 미래는 치킨집?
---------------------------------------------------------------
*정철환 팀장은 삼성SDS, 한양대학교 겸임교수를 거쳐 현재 동부제철 IT기획팀장이다. 저서로는 ‘SI 프로젝트 전문가로 가는 길’이 있으며 삼성SDS 사보에 1년 동안 원고를 쓴 경력이 있다. 한국IDG가 주관하는 CIO 어워드 2012에서 올해의 CIO로 선정됐다. ciokr@idg.co.kr
원문보기:
http://www.ciokorea.com/news/39711#csidx0ddb62e665e4a7f92bfc051225ba555 
Ucloud 디스크 마운트
2018. 10. 30. 14:02
파티션 정보 확인
[root@server /]# fdisk -l
Disk /dev/xvda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0009458d
Device Boot Start End Blocks Id System
/dev/xvda1 * 1 131 1048576 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/xvda2 131 392 2097152 82 Linux swap / Solaris
Partition 2 does not end on cylinder boundary.
/dev/xvda3 392 2611 17824768 83 Linux
Disk /dev/xvdb: 85.9 GB, 85899345920 bytes
255 heads, 63 sectors/track, 10443 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
파티션 만들기
[root@server /]# fdisk /dev/xvdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0xd56ebe5a.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): m <<= 도움말 보기
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help): p <<= 파티션 테이블 확인
Disk /dev/xvdb: 85.9 GB, 85899345920 bytes
255 heads, 63 sectors/track, 10443 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xd56ebe5a
Device Boot Start End Blocks Id System
Command (m for help): n <<= 새 파티션을 추가
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1 <<= 1번 파티션 입력
First cylinder (1-10443, default 1): 엔터(기본으로 1 적용)
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-10443, default 10443): 엔터(기본으로 10443 적용)
Using default value 10443
Command (m for help): t <<= 생성한 파티션의 id를 선택하기 위해 입력
Selected partition 1
Hex code (type L to list codes): L <<= 타입 리스트 확인
0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
1 FAT12 39 Plan 9 82 Linux swap / So c1 DRDOS/sec (FAT-
2 XENIX root 3c PartitionMagic 83 Linux c4 DRDOS/sec (FAT-
3 XENIX usr 40 Venix 80286 84 OS/2 hidden C: c6 DRDOS/sec (FAT-
4 FAT16 <32M 41 PPC PReP Boot 85 Linux extended c7 Syrinx
5 Extended 42 SFS 86 NTFS volume set da Non-FS data
6 FAT16 4d QNX4.x 87 NTFS volume set db CP/M / CTOS / .
7 HPFS/NTFS 4e QNX4.x 2nd part 88 Linux plaintext de Dell Utility
8 AIX 4f QNX4.x 3rd part 8e Linux LVM df BootIt
9 AIX bootable 50 OnTrack DM 93 Amoeba e1 DOS access
a OS/2 Boot Manag 51 OnTrack DM6 Aux 94 Amoeba BBT e3 DOS R/O
b W95 FAT32 52 CP/M 9f BSD/OS e4 SpeedStor
c W95 FAT32 (LBA) 53 OnTrack DM6 Aux a0 IBM Thinkpad hi eb BeOS fs
e W95 FAT16 (LBA) 54 OnTrackDM6 a5 FreeBSD ee GPT
f W95 Ext'd (LBA) 55 EZ-Drive a6 OpenBSD ef EFI (FAT-12/16/
10 OPUS 56 Golden Bow a7 NeXTSTEP f0 Linux/PA-RISC b
11 Hidden FAT12 5c Priam Edisk a8 Darwin UFS f1 SpeedStor
12 Compaq diagnost 61 SpeedStor a9 NetBSD f4 SpeedStor
14 Hidden FAT16 <3 63 GNU HURD or Sys ab Darwin boot f2 DOS secondary
16 Hidden FAT16 64 Novell Netware af HFS / HFS+ fb VMware VMFS
17 Hidden HPFS/NTF 65 Novell Netware b7 BSDI fs fc VMware VMKCORE
18 AST SmartSleep 70 DiskSecure Mult b8 BSDI swap fd Linux raid auto
1b Hidden W95 FAT3 75 PC/IX bb Boot Wizard hid fe LANstep
1c Hidden W95 FAT3 80 Old Minix be Solaris boot ff BBT
1e Hidden W95 FAT1
Hex code (type L to list codes): 8e <<= Linux LVM 타입으로 선택
Changed system type of partition 1 to 8e (Linux LVM)
Command (m for help): w <<= 생성한 테이블 정보를 저장
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
파티션 확인
[root@server /]# fdisk -l
Disk /dev/xvda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0009458d
Device Boot Start End Blocks Id System
/dev/xvda1 * 1 131 1048576 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/xvda2 131 392 2097152 82 Linux swap / Solaris
Partition 2 does not end on cylinder boundary.
/dev/xvda3 392 2611 17824768 83 Linux
Disk /dev/xvdb: 85.9 GB, 85899345920 bytes
255 heads, 63 sectors/track, 10443 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xd56ebe5a
Device Boot Start End Blocks Id System
/dev/xvdb1 1 10443 83883366 8e Linux LVM
LV(Logical Volume) 작업 - PV(Pysical Volume) 생성
[root@server /]# pvcreate /dev/xvdb1
Physical volume "/dev/xvdb1" successfully created
LV(Logical Volume) 작업 - PV 생성 확인
[root@server /]# pvscan
PV /dev/xvdb1 lvm2 [80.00 GiB]
Total: 1 [80.00 GiB] / in use: 0 [0 ] / in no VG: 1 [80.00 GiB]
LV(Logical Volume) 작업 - PV 정보 보기
[root@server /]# pvdisplay
"/dev/xvdb1" is a new physical volume of "80.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdb1
VG Name
PV Size 80.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID Q3LGAX-jhK4-w6eL-XA3t-Y1Mg-ICP0-IFzBOE
LV(Logical Volume) 작업 - VG(Volume Group) 생성
[root@server /]# vgcreate DataVG /dev/xvdb1
Volume group "DataVG" successfully created
LV(Logical Volume) 작업 - VG 생성 확인
[root@server /]# pvscan
PV /dev/xvdb1 VG DataVG lvm2 [80.00 GiB / 80.00 GiB free]
Total: 1 [80.00 GiB] / in use: 1 [80.00 GiB] / in no VG: 0 [0 ]
LV(Logical Volume) 작업 - VG 정보 보기
[root@server /]# vgdisplay
--- Volume group ---
VG Name DataVG
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size 80.00 GiB
PE Size 4.00 MiB
Total PE 20479
Alloc PE / Size 0 / 0
Free PE / Size 20479 / 80.00 GiB
VG UUID 7aEQ4r-ecmp-1S5r-mcId-YIFB-aLXf-CLSTJc
LV(Logical Volume) 작업 - LV(Logical Volume) 생성
[root@server /]# lvcreate -L 80g -n Data00 DataVG
Volume group "DataVG" has insufficient free space (20479 extents): 20480 required.
[root@server /]# lvcreate -l 20479 -n Data00 DataVG
Logical volume "Data00" created
LV(Logical Volume) 작업 - LV 정보 보기
[root@server /]# lvdisplay
--- Logical volume ---
LV Path /dev/DataVG/Data00
LV Name Data00
VG Name DataVG
LV UUID NiQ37f-ilLm-m5iE-JNEl-UBP1-eNJt-mgQA7r
LV Write Access read/write
LV Creation host, time VM1495178951968.localdomain, 2018-09-18 22:02:07 +0900
LV Status available
# open 0
LV Size 80.00 GiB
Current LE 20479
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
파일 시스템 생성
[root@server /]# mkfs.ext3 /dev/DataVG/Data00
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
5242880 inodes, 20970496 blocks
1048524 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
640 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 24 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
마운트 작업 - 마운트 할 디렉토리 생성
[root@server /]# mkdir /data
마운트 작업 - /dev/DataVG/Data00를 /data에 마운트
[root@server /]# mount /dev/DataVG/Data00 /data
마운트 작업 - 마운트 확인
[root@server /]# mount
/dev/xvda3 on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw)
/dev/xvda1 on /boot type ext4 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
none on /proc/xen type xenfs (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
/dev/mapper/DataVG-Data00 on /data type ext3 (rw)
[root@server /]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/xvda3 17G 15G 1.4G 92% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
/dev/xvda1 1008M 56M 901M 6% /boot
/dev/mapper/DataVG-Data00
79G 184M 75G 1% /data
마운트 작업 - /etc/fstab에 마운트 정보 추가
[root@server /]# vi /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed Mar 16 15:52:09 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=cc0565f7-adc2-4995-92d8-03d03830e0b3 / ext4 defaults 1 1
UUID=ab5b8d4a-1997-4b82-a764-05dbdf44dac2 /boot ext4 defaults 1 2
UUID=5cb8d624-6c99-478d-b05d-566b756ae6a5 swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
/dev/DataVG/Data00 /data ext3 defaults 1 2 <<= 추가한 내용
'Server' 카테고리의 다른 글
| [ELK] Elasticsearch 에 Security를 적용하려했더니?! (0) | 2018.12.20 |
|---|---|
| [ELK] Elasticsearch 와 Kibana 모니터링 하기 (0) | 2018.12.20 |
| [ELK] Spring + Logstash + Elasticsearch + Kibana 기본 셋팅 (0) | 2018.12.20 |
| [Redis] 윈도우에 Redis 설치하기 (0) | 2018.12.19 |
| 웹서버 트래픽 폭주 대비하기 (0) | 2018.11.02 |